近日,小红书正式开源了其自主研发的 MoE 大模型 dots.llm1,为开源社区注入新活力。这款模型在多个基准测试中展现出卓越性能,超越了 Qwen3,但略逊于 DeepSeek-V3,标志着小红书在通用大模型领域迈出了重要一步。
在AI大模型领域,开源与创新正成为行业发展的重要驱动力。 近日,知名内容社区平台小红书正式宣布开源其自主研发的MoE大模型——dots.llm1。 这一举动不仅为大模型开源社区增添了新的力量,也展示了小红书在通用人工智能技术上的深厚积累。
HF演示空间
dots.llm1 的开源,意味着全球开发者和研究人员可以访问其模型权重、架构细节以及相关工具,从而促进技术的交流与合作,加速MoE模型在不同应用场景的探索和落地。
MoE 架构的优势与 dots.llm1 的亮点
dots.llm1 采用了当前前沿的 MoE 架构,这种架构通过激活模型中部分“专家”网络来处理输入,从而在提升模型性能的同时,显著降低推理成本。 相比于传统的密集型模型,MoE 模型能够在参数量巨大的情况下,实现更高效的计算。
dots.llm1 的主要亮点包括
- 高效的 MoE 架构 通过稀疏激活机制,模型在处理不同任务时能够动态选择最适合的专家,从而提高推理速度和效率。
- 出色的中文处理能力 作为源自小红书的模型,dots.llm1 在中文语料上进行了充分训练,预计在中文理解、生成和对话方面表现优异,尤其是在中文内容社区相关的任务上。
- 开放性和可扩展性 开源模式将鼓励社区对其进行微调和优化,以适应更广泛的垂直领域应用。
性能评测 超越 Qwen3 逼近 DeepSeek-V3
小红书对 dots.llm1 进行了多项基准测试,结果显示其性能表现亮眼
- 超越 Qwen3 在多个通用能力基准测试中,dots.llm1 的表现均优于此前广泛使用的 Qwen3 模型。 这表明小红书在模型架构和训练策略上取得了显著进步,使其能够超越业界主流的同类开源模型。
- 略逊于 DeepSeek-V3 尽管 dots.llm1 表现强劲,但与业界顶尖的 MoE 模型 DeepSeek-V3 相比,仍存在一定差距。 DeepSeek-V3 以其卓越的性能和效率在MoE领域树立了新的标杆,dots.llm1 的表现虽然未完全达到,但差距已不大,这为未来的优化和迭代留下了巨大的想象空间。
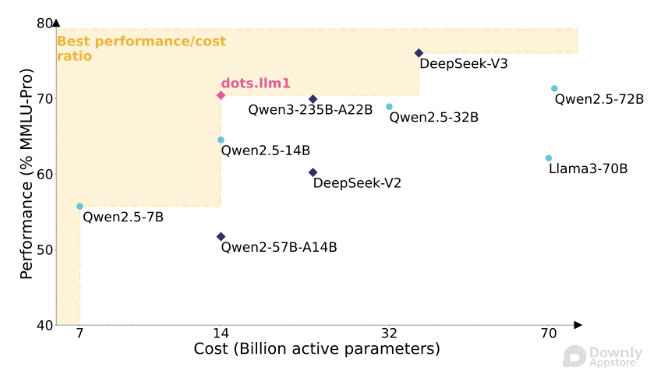
这次性能评估,也进一步凸显了 MoE 架构在兼顾性能与效率方面的巨大潜力。 尽管 dots.llm1 在某些方面未能完全达到顶尖水平,但作为一款新晋开源的 MoE 模型,其展现出的实力已经足以令人期待。
小红书在 AGI 领域的布局与影响
dots.llm1 的开源,是小红书在通用人工智能(AGI)领域战略布局的重要一步。 作为一家以内容社区为核心的公司,小红书拥有海量的优质图文和视频数据,这些数据将为其未来大模型的训练和优化提供得天独厚的优势。
此次开源的意义在于
- 赋能社区 通过开放核心技术,小红书可以吸引更多的开发者和研究人员共同参与到大模型生态的建设中来,加速技术创新。
- 推动行业发展 增加高性能开源 MoE 模型的供给,有助于降低企业和开发者使用 MoE 模型的门槛,推动 MoE 架构在更多实际场景中的应用。
- 提升自身影响力 通过开源,小红书不仅贡献了技术,也提升了自身在 AI 领域的品牌形象和影响力,有望吸引更多AI人才。
未来展望
随着 dots.llm1 的开源,我们可以预见,基于 MoE 架构的大模型将迎来更广泛的关注和应用。 小红书的这一举动,无疑为国内乃至全球的开源大模型生态注入了新的活力。 未来,我们期待看到 dots.llm1 在社区的共同努力下,不断优化迭代,在性能上进一步逼近甚至超越现有顶尖模型,并在更多创新应用场景中发挥关键作用。



2025 AI 技术峰会

AI 实战课程
热门工具
AI 助手
智能对话,提升效率
智能图像处理
一键美化,智能修图
AI 翻译
多语言实时翻译



评论 (0)
暂无评论,快来发表第一条评论吧!