近日,北京大学和加州大学伯克利分校的研究团队联合发布了一项对当前最强大型语言模型驱动的 Agent(AI 智能体)的全面评测结果。 通过名为 IDA-Bench 的严格基准测试,研究发现,即使是顶尖的 Agent 在复杂环境下的表现也远不及人类水平,最高得分仅为 40 分(满分 100 分),揭示了当前 AI Agent 在智能决策、自主探索和复杂任务处理能力上的瓶颈与未来发展方向。
随着大型语言模型 (LLM) 技术的飞速发展,能够自主规划、执行复杂任务的 AI 智能体 (Agent) 正成为人工智能领域的新焦点。 它们被寄予厚望,有望在各个领域取代人类完成重复性、复杂性的工作。 然而,这些“最强大脑”的实际能力究竟如何?
IDA-Bench 一项全新的Agent评测基准
为了更准确地评估 AI Agent 的真实能力,研究团队设计了 IDA-Bench。 这一基准测试与以往的评测方法有显著不同
- 复杂、开放式任务 IDA-Bench 不仅仅是评估模型生成文本的能力,而是聚焦于 Agent 在多步骤、开放式且需要自主决策和探索的复杂环境中的表现。 例如,Agent 可能需要在给定指令下,通过与环境交互来解决谜题、完成挑战。
- 指令驱动决策 评测的核心是 Agent 理解并遵循人类指令的能力,以及在执行指令过程中,面对未知和不确定性时,如何进行有效的决策和规划。
- 多维度评估 评估维度涵盖了 Agent 的任务完成度、探索效率、决策智能性等多个方面,力求全面反映 Agent 的实际操作能力。
通过引入这些挑战性的元素,IDA-Bench 旨在模拟真实世界中 Agent 可能面临的复杂场景,从而更客观地衡量它们的智能水平。
最强Agent也只有40分 远不及人类表现
测试结果令人深思。 在 IDA-Bench 的各项任务中,即使是基于目前最先进的大型语言模型构建的 Agent,其表现也显得力不从心
- 最高得分仅40分 在所有参评的 Agent 中,表现最好的也只获得了 40 分(满分 100 分),与人类轻松达成高分形成鲜明对比。 这意味着在许多复杂任务上,Agent 仍然难以胜任。
- 智能决策与规划不足 Agent 在面对需要多步推理、长程规划和灵活应变的任务时,尤其显得力不从心。 它们往往难以理解指令的深层含义,或在执行过程中陷入局部最优,无法找到全局最佳解决方案。
- 自主探索能力欠缺 在开放式环境中,Agent 缺乏高效的自主探索策略,容易遗漏关键信息或重复无效操作,导致任务失败。
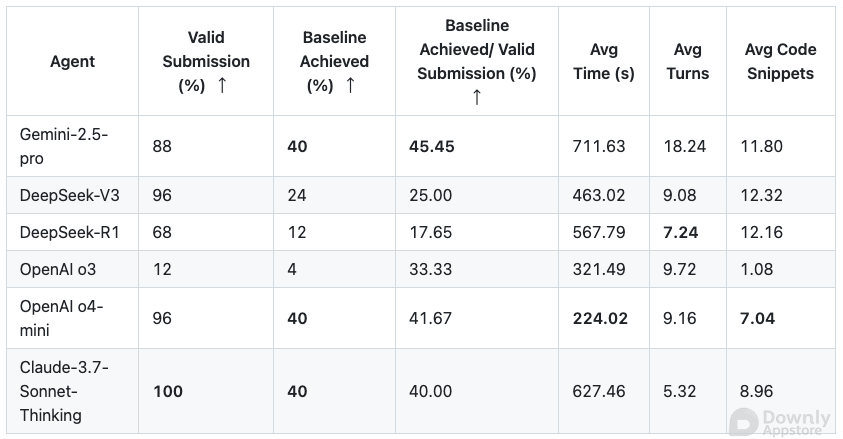
这些结果表明,尽管大模型在语言理解和生成方面取得了巨大进步,但将其应用于复杂的具身或模拟环境中,使其真正具备“智能”行为,仍面临巨大挑战。
当前Agent的瓶颈与未来发展方向
这项研究不仅揭示了当前 AI Agent 的能力短板,也为未来的研究指明了关键方向
1. 强化长程规划与推理能力
目前的 Agent 往往只能进行短期的、局部性的规划。 未来需要研究更强大的规划算法,使 Agent 能够理解任务的全局目标,并制定多步骤、长期的执行策略。
2. 提升自主探索与环境感知能力
Agent 需要更智能的探索机制,能够高效地收集环境信息,并利用这些信息进行决策。 结合视觉、听觉等多模态感知能力,将有助于 Agent 更好地理解复杂环境。
3. 增强容错与适应性
真实世界充满不确定性。 Agent 需要具备更强的容错能力,能够在遇到意外情况或错误时,进行自我纠正和适应性调整,而不是直接失败。
4. 融合世界模型与具身智能
将类似于 Meta AI V-JEPA 2 这样的“世界模型”融入 Agent,使其能够对环境的动力学进行预测,从而更好地规划和执行任务,是未来研究的重要方向。 让 Agent 不仅仅是“回答问题”,而是真正能够“行动”起来。
展望 更智能的AI Agent未来可期
北大与伯克利分校的这项研究,如同一面镜子,清晰地反映了当前 AI Agent 发展所处的阶段。 它提醒我们,尽管取得了巨大进步,但要实现真正通用、自主的 AI Agent,仍有漫长的道路要走。 这项工作为研究人员提供了宝贵的基准和研究方向,有望加速下一代更强大、更智能的 AI Agent 的诞生,使其未来能真正成为人类的得力助手。




2025 AI 技术峰会

AI 实战课程
热门工具
AI 助手
智能对话,提升效率
智能图像处理
一键美化,智能修图
AI 翻译
多语言实时翻译



评论 (0)
暂无评论,快来发表第一条评论吧!