针对 AI 视频生成中常见的“角色崩坏”与“环境闪烁”痛点,字节跳动联合南洋理工大学推出了 StoryMem 系统。该方案通过模拟人类记忆机制,构建混合记忆库,成功实现了跨场景的长视频内容一致性,且训练成本极低。
记忆引擎 混合记忆库锁定视觉核心
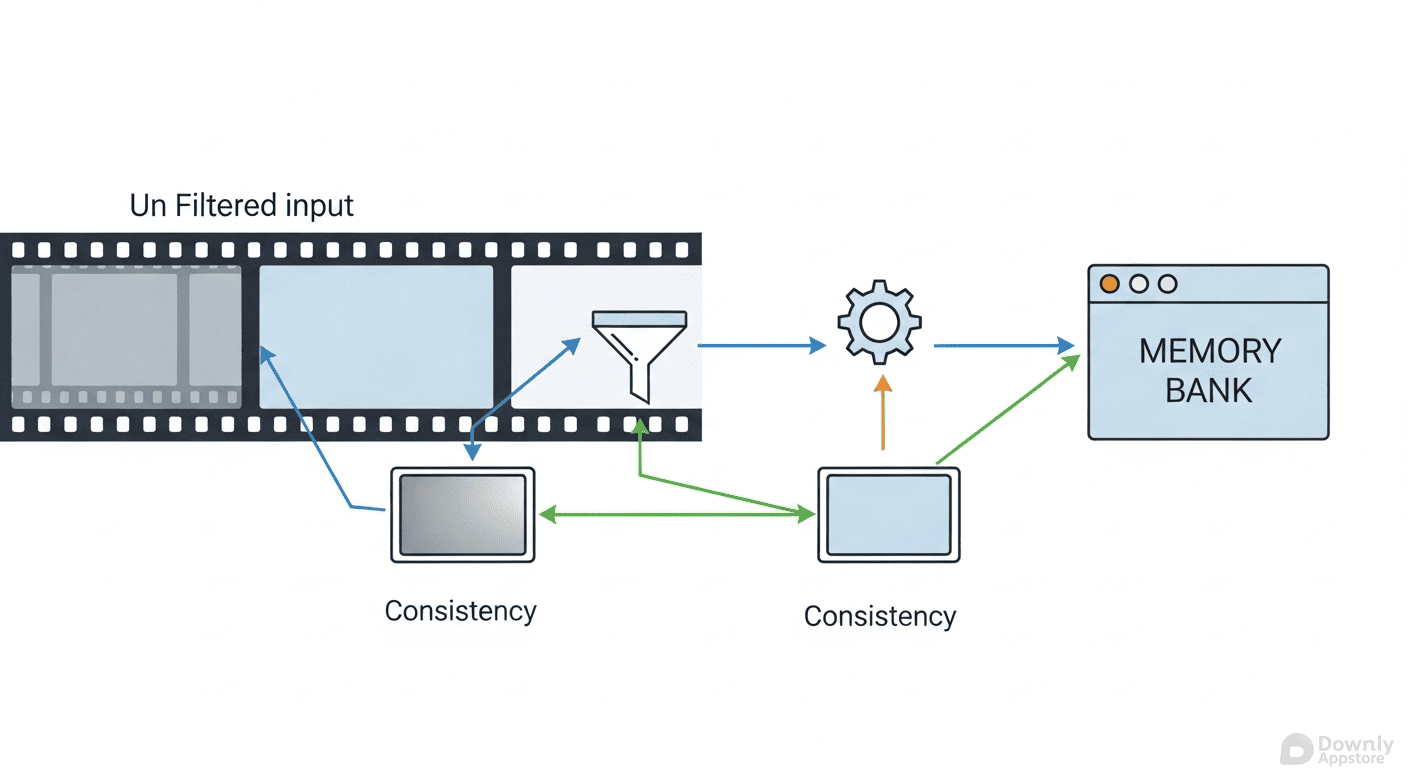
在 Sora、Kling 等现有模型中,随着视频时长的增加,多镜头叙事往往会导致角色长相突变或背景细节丢失。StoryMem 的核心突破在于引入了独特的“混合记忆库”(Hybrid Memory Bank)设计。
系统摒弃了将所有历史帧强行塞入模型的低效做法,转而采用双重过滤器机制:首先通过语义分析挑选出最具代表性的视觉核心帧,随后利用质量检测剔除模糊图像。这种选择性记忆策略,既保留了关键叙事线索,又避免了计算成本的指数级增长,从根本上保证了角色形象在不同场景间的稳定性。
算法创新 负时间索引重塑时空逻辑
StoryMem 的另一大创新是引入了 RoPE(旋转位置嵌入)技术,并创造性地赋予记忆帧“负时间索引”。这一操作引导 AI 模型将参考帧识别为“已经发生的过去”,从而在生成新场景时,能够基于“记忆”进行连贯推演,而非凭空捏造。
该系统基于阿里巴巴开源的 Wan2.2-I2V 模型构建,在140亿参数的基础模型上仅增加了约7亿参数的 LoRa 权重,展现了极高的训练效率。在 ST-Bench 基准测试中,StoryMem 的跨场景一致性提升了28.7%,在美学得分与用户偏好上全面超越了 HoloCine 等竞品。目前,该项目已在 Hugging Face 开放权重,为开发者探索长视频叙事提供了强有力的工具。




2025 AI 技术峰会

AI 实战课程
热门工具
AI 助手
智能对话,提升效率
智能图像处理
一键美化,智能修图
AI 翻译
多语言实时翻译



评论 (0)
暂无评论,快来发表第一条评论吧!