近期研究揭示,大型语言模型 (LLM) 在长期的多轮对话中可能遭遇“迷失”困境,表现为对早期对话内容的遗忘或误解,导致回复质量下降。这一现象对 LLM 在复杂交互场景中的应用构成了挑战,并促使研究人员深入探究其成因与解决方案。
LLM 在多轮对话中“迷失”
大型语言模型 (LLM) 在生成式人工智能领域取得了革命性进展,在问答、内容创作等方面展现出惊人能力。 然而,当这些模型被应用于长时间、多轮次的复杂对话场景时,一个令人担忧的现象逐渐浮出水面——它们似乎会“迷失方向”,即对早期对话内容出现遗忘、误解甚至前后矛盾的情况。
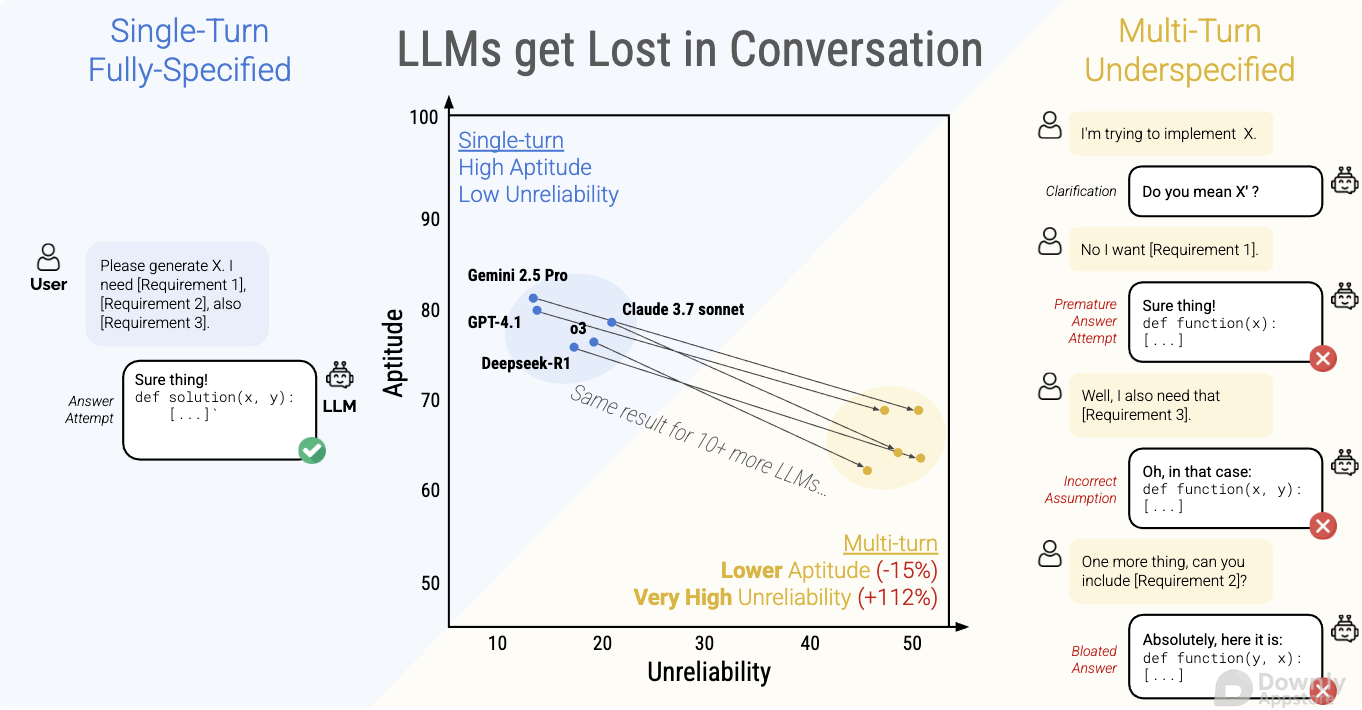
这一“迷失”现象引起了学术界和工业界的广泛关注,因为它直接影响了 LLM 在客户服务、智能助理、教育辅导等需要持续交互场景中的可靠性和用户体验。 一项最新研究深入探讨了这一问题,揭示了其潜在的成因和对模型表现的负面影响。
“迷失”现象的根源
研究表明,LLM 在多轮对话中“迷失”并非单一原因造成,而是多种因素共同作用的结果
- 有限的上下文窗口 尽管现代 LLM 拥有庞大的上下文窗口,但与真实世界中无限的记忆和理解能力相比,其上下文处理能力仍然是有限的。 当对话轮次和信息量不断增加,早期对话内容可能会被“挤出”上下文窗口,导致模型无法回顾和利用。
- 注意力机制的衰减 LLM 依赖注意力机制来权衡不同信息的重要性。 随着对话长度增加,模型可能难以维持对早期关键信息的有效关注,注意力权重可能会在更近期的对话内容上过度集中,从而“忘记”了最初的语境或指令。
- 信息过载与噪声 持续的对话会产生大量信息,其中既有关键内容,也可能包含冗余或低价值的“噪声”。 模型在处理海量信息时,可能会被噪声干扰,难以准确提取和维持对核心信息的理解。
- 知识编辑的挑战 现有研究表明,即使模型能够“记住”部分上下文,但其对早期对话内容的“理解”也并非固定不变。 在后续对话中,新的信息或用户澄清可能会无意中“修改”或“覆盖”模型对早期概念的理解,导致知识编辑失败或产生矛盾。
- 指令遵循的漂移 在多轮对话中,用户的初始指令可能会随着对话的深入而逐渐模糊或被新的指令覆盖。 模型可能难以持续遵循最初的复杂指令,导致回答偏离预期。
对 LLM 应用的影响
“迷失”现象对 LLM 在实际应用中的性能和可靠性构成了严峻挑战
- 用户体验下降 当 LLM 无法记住或正确理解早期对话内容时,用户会感到沮丧,认为模型不够智能或缺乏“记忆力”,从而降低对 AI 助手的信任度。
- 任务完成率降低 在需要持续上下文理解的任务中,例如排查故障、法律咨询或复杂项目协作,LLM 的“迷失”可能导致无法有效推进对话,甚至给出错误或无关的建议,从而影响任务的成功完成。
- 安全与伦理风险 在某些敏感场景,例如医疗诊断或金融建议,如果 LLM 遗忘关键信息并给出错误建议,可能带来严重的安全和伦理问题。
探索解决方案
为了解决 LLM 在多轮对话中“迷失”的问题,研究人员正在积极探索多种途径
- 优化上下文管理策略 研发更高效的上下文压缩、总结和检索技术,确保模型能够更智能地管理和利用有限的上下文窗口,例如引入外部记忆模块或长程注意力机制。
- 提升模型对关键信息的持久性 设计新的模型架构或训练方法,使模型能够更长时间地保持对对话中关键信息和初始指令的关注,减少注意力衰减。
- 引入“自我纠错”机制 允许模型在对话过程中主动识别和纠正自身对早期对话内容的误解或遗忘,例如通过与用户进行确认或内部验证。
- 强化学习与人类反馈 利用强化学习从人类反馈中学习,提升模型在复杂对话场景中保持一致性和连贯性的能力。
- 分层对话管理 引入分层结构,将对话拆分为更小的子任务或主题,并在每个子任务中维护独立的上下文,从而降低单次上下文窗口的压力。
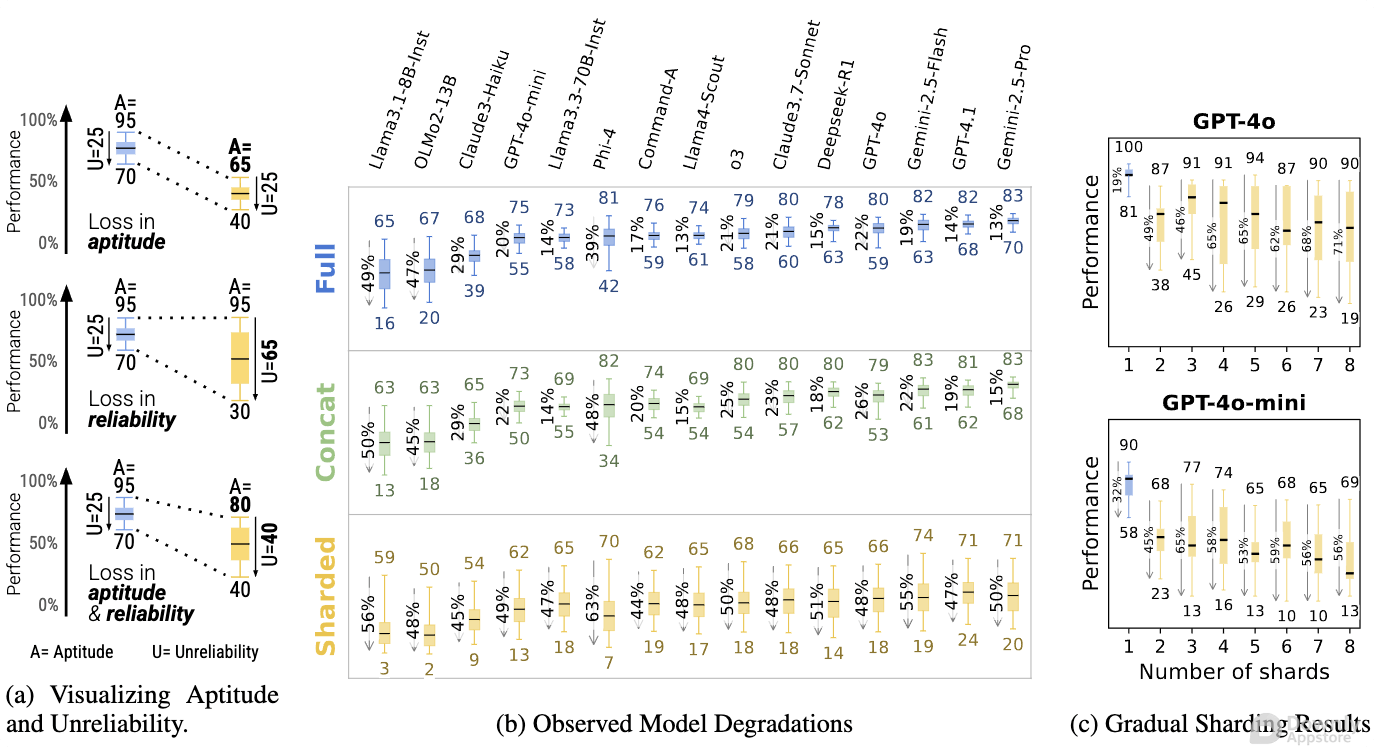
未来展望
LLM 在多轮对话中“迷失”的问题,是当前大型语言模型研究领域的一个重要挑战。 随着模型规模的不断扩大和技术的持续创新,我们有理由相信,研究人员将能够开发出更鲁棒、更智能的对话模型,使其在复杂交互场景中表现得更加出色,真正实现“永不迷失”的智能对话体验。 解决这一问题,将是推动 LLM 从“天才”走向“可靠伙伴”的关键一步。




2025 AI 技术峰会

AI 实战课程
热门工具
AI 助手
智能对话,提升效率
智能图像处理
一键美化,智能修图
AI 翻译
多语言实时翻译



评论 (0)
暂无评论,快来发表第一条评论吧!