 Stable Diffusion
Stable Diffusion
应用简介
Stable Diffusion 是开源领域最强大的AI绘画模型,其核心优势在于强大的技术生态系统。
Stable Diffusion 模型架构基于潜在扩散技术,通过一系列创新扩展实现突破性能力:ControlNet实现精确构图控制;LORA技术以小型文件实现高效风格微调;FLUX技术优化训练流程提升生成质量。ComfyUI、AUTOMATIC1111等开源界面大幅降低使用门槛,而DreamBooth、Textual Inversion等个性化训练方法则让创作者能打造专属模型。随着XL、SDXL Turbo等版本迭代,Stable Diffusion持续引领开源AI绘画领域创新潮流,为创作者提供前所未有的创意可能性。
主要特性
- 1基于潜在扩散的开源AI绘图引擎
- 2高质量文本到图像生成能力
- 3强大的图像编辑与变换功能
- 4ControlNet精确构图与姿态控制
- 5LORA与Textual Inversion个性化训练
- 6FLUX技术大幅提升生成质量与速度
- 7丰富的社区模型与插件生态系统
- 8跨平台兼容(Nvidia、AMD、CPU)
- 9支持本地私有化低成本部署
详细信息
Stable Diffusion,作为近年来人工智能领域最具突破性的开源项目之一,已深刻改变了视觉内容的创作与编辑方式。从其核心技术原理到广泛的应用场景,从活跃的社区生态到令人期待的未来发展,这项技术正在不断重塑数字创意的边界。
技术原理 - 潜在扩散模型
Stable Diffusion的核心技术基于“潜在扩散模型”(Latent Diffusion Models, LDMs)。这一创新方法由Robin Rombach (Stability AI), Andreas Blattmann (LMU Munich), Dominik Lorenz (LMU Munich), Patrick Esser (Runway ML), Björn Ommer (LMU Munich) 等人共同提出,并由德国慕尼黑大学(LMU Munich)的CompVis研究组主要开发,后续由Stability AI公司进一步推动和普及。
与传统的直接在像素空间操作的扩散模型不同,潜在扩散模型在**压缩的、低维的潜在空间(latent space)**中进行操作。
这一关键区别带来了显著优势:
- 大幅降低计算资源需求:在低维空间处理数据,显著减少了计算量。
- 加快图像生成速度:更少的数据处理意味着更快的生成时间。
- 实现更高效的训练过程:模型训练同样受益于数据维度的降低。
潜在扩散的工作流程大致如下:首先,一个强大的自编码器(autoencoder)将高分辨率图像压缩(编码)到一个维度小得多的潜在表示中;然后,扩散过程在这个潜在空间中逐步去除噪声并根据文本提示(或其他条件)生成内容;最后,解码器将潜在空间中的表示转换(解码)回完整的像素图像。这种方法使得处理和生成高分辨率图像的任务变得更加高效和可行。
发展历程 - 从实验室到全球社区
Stable Diffusion的发展可以清晰地划分为几个关键阶段:
- 初始研究与论文发表:2021年底至2022年初,潜在扩散模型的理论基础和初步成果通过论文《High-Resolution Image Synthesis with Latent Diffusion Models》公之于众。
- 公开发布:2022年8月,Stability AI正式发布了Stable Diffusion 1.0版本,这是首个向公众开放的高质量、开源的文本到图像生成模型。
- 社区爆发与WebUI的崛起:随着AUTOMATIC1111的Stable Diffusion WebUI等用户友好型开源界面的出现,Stable Diffusion的使用门槛大幅降低,迅速点燃了全球创作者的热情。
- 技术迭代与模型增强:从1.0、1.4、1.5,到2.0、2.1,再到SDXL (Stable Diffusion XL) 及其优化版本如SDXL Turbo,模型在图像质量、提示词理解、生成多样性等方面持续进化。
- FLUX技术登场:2024年初,Stability AI推出了FLUX系列模型(如FLUX.1),作为Stable Diffusion技术路线的下一代演进,旨在进一步提升生成质量和效率。
这种开放、快速迭代的发展模式,使Stable Diffusion迅速成为AI艺术创作领域的主流工具之一,并催生了一个庞大、活跃且富有创造力的用户和开发者社区。
Stable Diffusion WebUI - 民主化AI创作的关键推手
在Stable Diffusion的普及过程中,AUTOMATIC1111的Stable Diffusion WebUI扮演了至关重要的角色。它不仅仅是一个用户界面,更是整个生态系统的核心枢纽和创新催化剂。
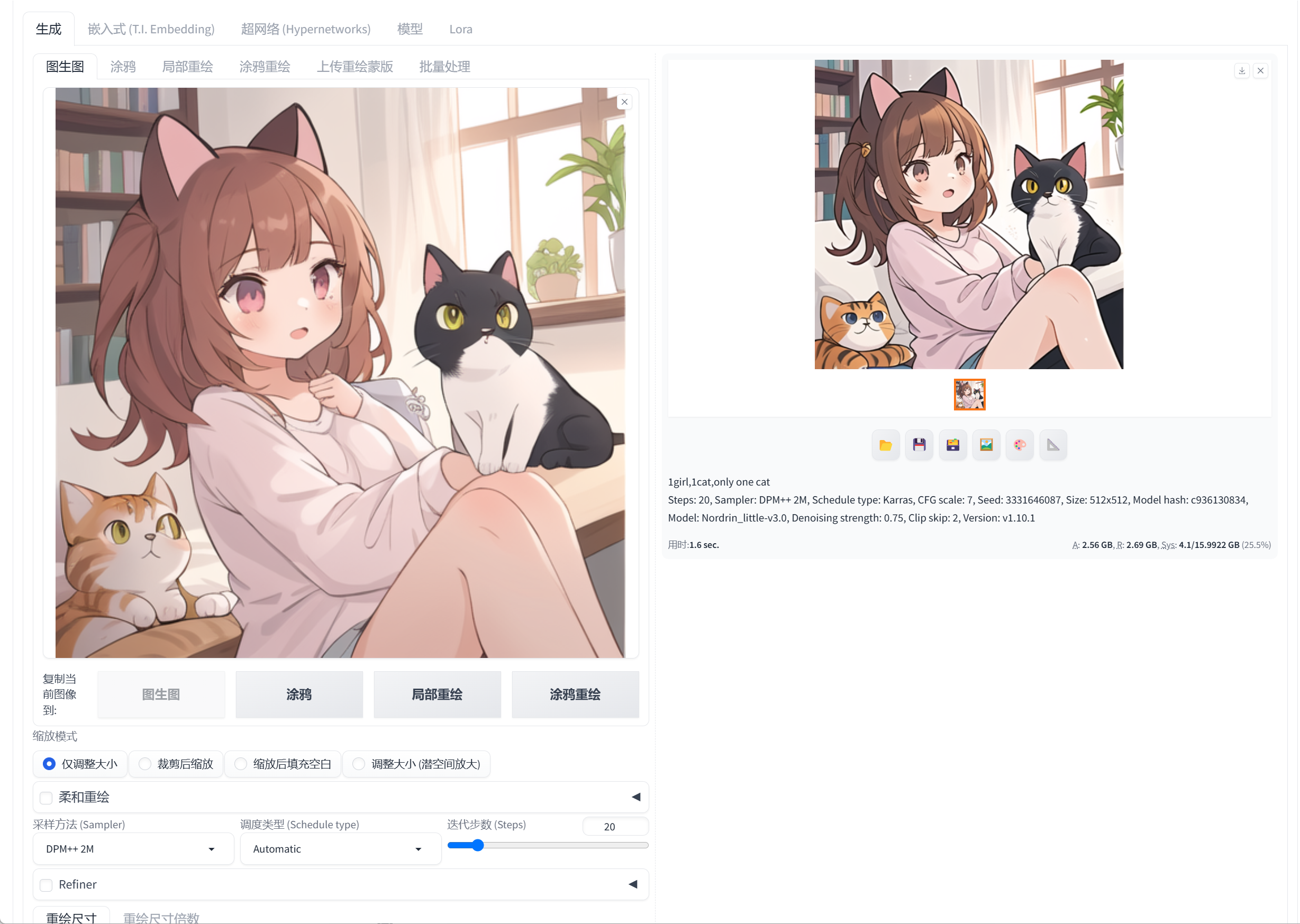
文生图:
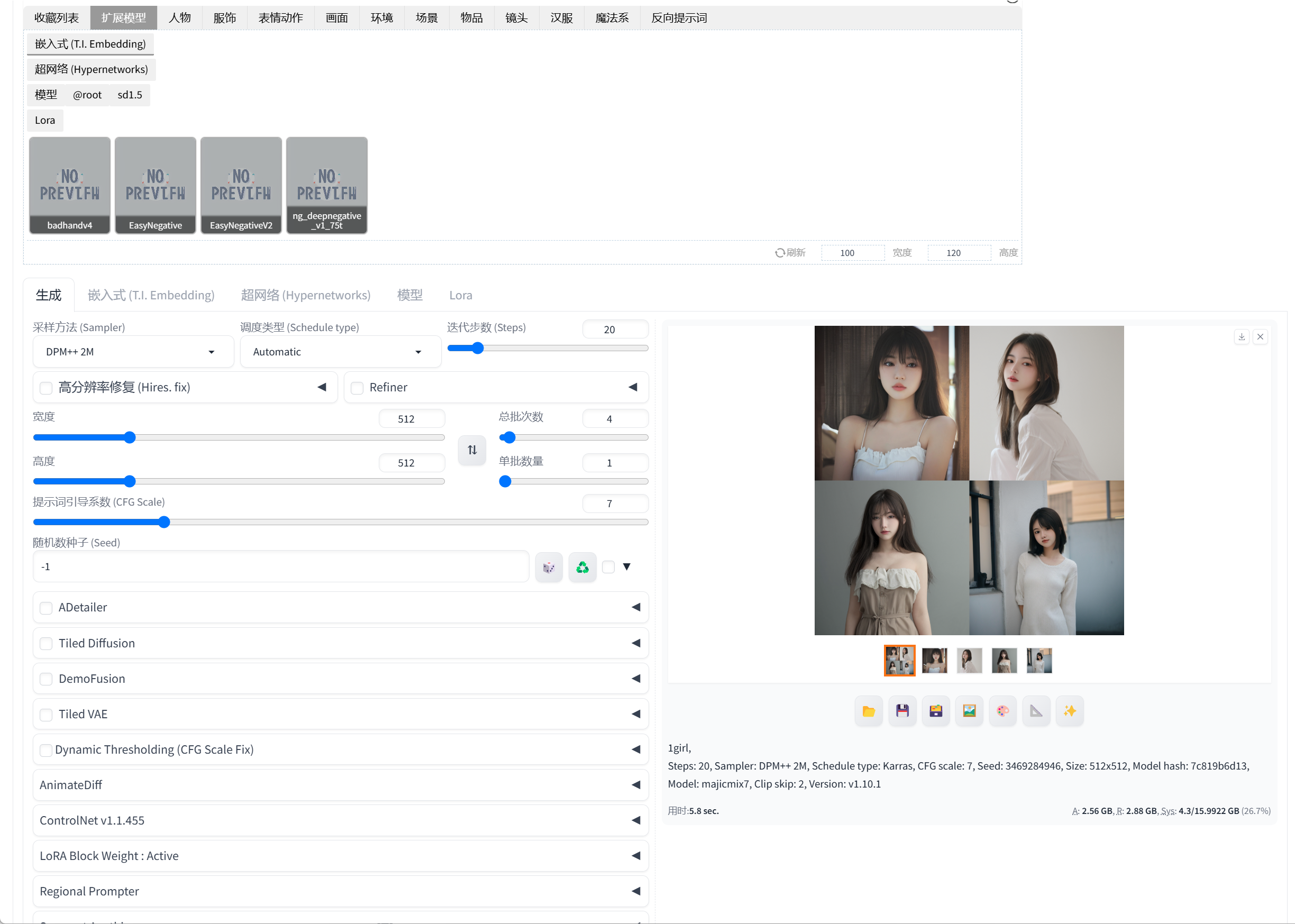
文生图效果:
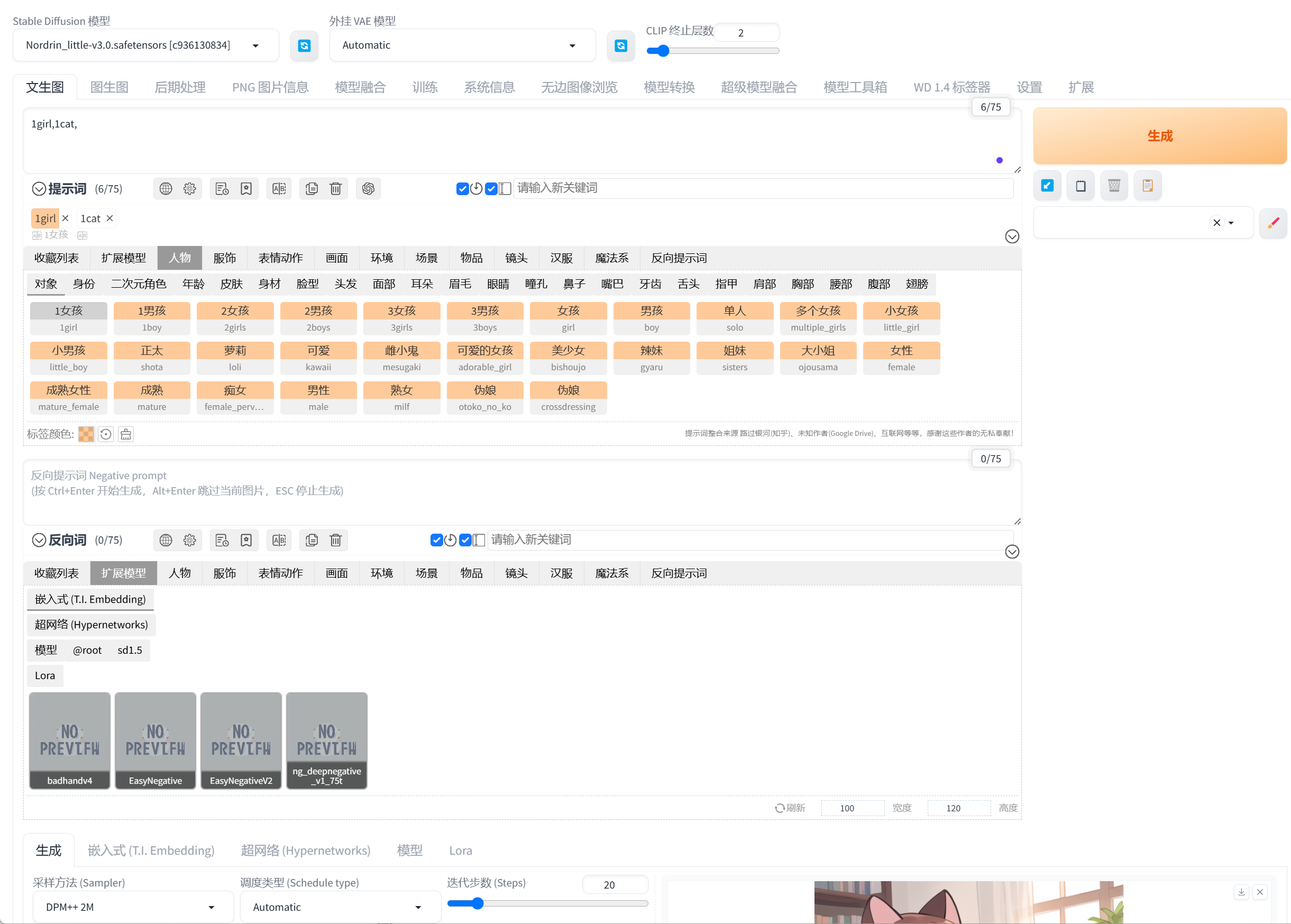
图像参数配置:
WebUI的重大意义
- 极致降低技术门槛:通过直观的图形界面,将复杂的命令行操作和参数调整变得简单易懂,使得没有编程背景的普通用户也能轻松上手,体验AI创作的乐趣。
- 强大功能整合与扩展性:集成了文本到图像、图像到图像、局部重绘(Inpainting)、图像扩展(Outpainting)、ControlNet、LoRA/LyCORIS模型加载与管理、脚本支持等海量功能,提供了一站式的创作平台。
- 繁荣的插件与脚本生态:其开放的插件(Extensions)和脚本(Scripts)架构,吸引了全球开发者贡献了成百上千的扩展功能,从特定风格的滤镜到复杂的动画生成工具,极大地丰富了WebUI的能力边界。
- 社区驱动的快速创新:WebUI本身作为一个开源项目,其开发和迭代完全由社区驱动,新功能、错误修复和性能优化能够以极快的速度被整合和发布。
- 简化本地化部署与管理:提供了相对便捷的一键安装脚本和详尽的社区文档,大幅简化了在个人计算机上部署和管理Stable Diffusion环境的流程。
可以说,Stable Diffusion WebUI不仅让Stable Diffusion技术“飞入寻常百姓家”,更通过其强大的整合能力和开放性,促进了模型训练、提示词工程、工作流分享等周边领域的繁荣,形成了一个充满活力的、自我强化的创新生态系统。它是AI技术民主化进程中一个里程碑式的典范。
核心功能与应用
文本到图像生成 (Text-to-Image)
这是Stable Diffusion最基础也最广为人知的功能。用户通过输入文本描述(Prompt),辅以否定提示词(Negative Prompt)来排除不希望出现的元素,模型便能生成符合描述的图像。这一功能广泛应用于概念艺术创作、广告设计、个性化头像生成、故事插画等领域。
示例提示词:
A photorealistic image of an astronaut riding a horse on the moon, dramatic lighting, high detail, 8k resolution, trending on ArtStation.
否定提示词:
blurry, low quality, cartoon, watermark, signature, text.
图像编辑与变换 (Image Editing & Transformation)
Stable Diffusion不仅能从零开始创作,还具备强大的图像编辑能力:
- 图像到图像 (Image-to-Image / img2img):用户提供一张初始图像和文本提示,模型会在保留初始图像结构和内容的基础上,根据文本提示进行风格转换或内容修改。
- 局部重绘 (Inpainting):通过蒙版(Mask)指定图像中的特定区域,模型可以智能地修复、替换或重新生成该区域的内容,同时与周围环境无缝融合。
- 图像扩展 (Outpainting):在现有图像的边界之外智能地扩展内容,创造出更广阔的场景或补充缺失的部分。
ControlNet - 精确控制生成过程
ControlNet是Stable Diffusion生态中一项革命性的扩展技术。它允许用户通过提供额外的控制条件图像(如边缘检测图、深度图、人体姿态骨骼图、线稿、语义分割图等),来更精确地指导图像的生成过程,例如控制生成图像的构图、物体姿态、轮廓形状等。这极大地增强了AI生成内容的可控性和实用性,使得艺术家和设计师能够将AI更好地融入其创作流程。
个性化训练 - LoRA与Textual Inversion (Dreambooth)
为了满足用户对特定风格、角色或物体的生成需求,Stable Diffusion社区发展出了多种高效的模型微调技术:
- LoRA/LyCORIS (Low-Rank Adaptation):一种轻量级的模型微调方法,允许用户使用相对较少的数据和计算资源,就能在预训练的大模型基础上训练出能够生成特定风格或角色的“小模型”。这些小模型文件体积小,加载迅速,易于分享。
- Textual Inversion (文本嵌入) / Dreambooth:这些技术允许用户通过少量样本图像,让模型“学习”并理解一个新的概念(如特定的人物、物体或画风),并将其与一个特定的关键词(触发词)绑定。之后,在提示词中使用这个关键词,就能生成包含该特定概念的图像。
这些技术使得创作者能够轻松地开发和使用具有高度个性化特征的AI模型,极大地扩展了Stable Diffusion的应用范围和创作可能性。
FLUX - 技术演进的新篇章
FLUX是由Stability AI于2024年初推出的新一代文本到图像生成模型系列。它代表了Stable Diffusion技术路线的最新发展方向,旨在解决现有模型的一些局限性,并在多个方面实现突破:
- 更高的图像质量与细节:FLUX模型致力于生成细节更丰富、伪影更少、整体视觉效果更逼真的图像。
- 更快的生成速度与效率:在保持或提升图像质量的同时,追求更快的推理速度,降低生成延迟。
- 更强的提示词理解与遵循能力:改进模型对复杂、细致文本提示的理解和执行能力,更准确地反映用户的意图。
- 优化的模型架构:可能采用新的网络结构或训练策略,以提升模型的整体性能和泛化能力。
FLUX可以被视为Stable Diffusion技术体系的进化版本,由同一核心理念驱动,但在模型设计、训练数据和性能表现上力求达到新的高度,为用户带来更强大的AI创作工具。
开源生态系统的力量
Stable Diffusion成功的核心要素之一是其蓬勃发展的开源生态系统:
- 多样化的前端界面与工具:除了AUTOMATIC1111 WebUI,还有InvokeAI, ComfyUI, SD.Next, Fooocus等众多优秀的开源前端和后端工具,满足不同用户的需求。
- 海量的社区模型与资源:Civitai等平台上汇聚了成千上万由社区成员训练和分享的Checkpoint大模型、LoRA、Textual Inversion、VAE、UPSCALE模型等资源。
- 活跃的开发者与创作者社区:全球开发者和创作者围绕Stable Diffusion进行持续的技术创新、教程分享、艺术探索和应用开发。
- 跨平台支持与优化:社区努力使得Stable Diffusion能够在Nvidia、AMD的GPU上高效运行,甚至在CPU和苹果M系列芯片上也能进行推理,不断降低硬件门槛。
这种开放、协作、共享的生态模式,使得技术创新能够快速传播、迭代和应用,形成了一个自我强化、不断壮大的创新循环。
本地部署与隐私优势
与许多依赖云端API的AI服务不同,Stable Diffusion及其相关工具链完全支持在个人计算机上进行本地化部署和运行。这带来了几个关键优势:
- 数据隐私与安全:所有输入数据(如提示词、初始图像)和生成内容都保留在用户本地,无需上传到任何第三方服务器,最大限度地保护了用户隐私和创作内容的机密性。
- 无持续性成本:一旦硬件配置满足要求,本地运行Stable Diffusion无需为每次生成支付API调用费用,创作数量和频率不受限制。
- 完全的控制权与自定义能力:用户可以自由选择和切换不同的模型、调整所有可用的生成参数、安装和组合各种扩展插件,实现高度个性化的创作流程。
- 离线工作能力:本地部署意味着即使在没有网络连接的情况下,用户依然可以进行AI创作。
这些特性使得Stable Diffusion成为对数据隐私、成本控制和创作自由度有较高要求的个人用户、艺术家、设计师以及中小型企业的理想选择。
未来展望
随着技术的不断发展和社区的持续创新,Stable Diffusion生态系统有望在以下方面取得进一步的突破:
-
多模态能力的深度整合:不仅仅是文本到图像,未来将更紧密地融合视频生成(Text-to-Video)、3D模型生成(Text-to-3D)、音频生成等多种模态,实现更丰富的跨媒体内容创作。
-
更高效、更易用的个性化训练方法:进一步降低训练自定义模型的门槛,让普通用户也能轻松创建符合个人需求的专属AI模型。
-
实时交互式生成:随着模型优化和硬件性能的提升,有望实现更低延迟甚至实时的图像生成与编辑反馈,提升创作的即时性和流畅性。
-
更强的语义理解与逻辑一致性:模型将能更准确地理解复杂的、包含多对象交互和抽象概念的提示词,并生成在逻辑上更连贯、细节上更一致的图像。
-
可解释性与可控性的增强:提供更多工具和方法来理解模型的决策过程,并赋予用户更精细化的控制手段来调整生成结果。
结论
Stable Diffusion不仅仅是一项强大的AI技术,更是一场由开源精神驱动的创意革命。它通过将先进的视觉生成能力赋予每一个拥有计算机的人,极大地民主化了艺术创作和内容生产的过程。从专业设计师到业余爱好者,从大型企业到独立创作者,Stable Diffusion及其繁荣的生态系统正在开启一个人机协作、想象力无限的数字创意新时代。
随着FLUX等新一代技术的涌现和全球社区的持续贡献与探索,Stable Diffusion必将在未来为更多领域带来深刻的创新和变革,继续拓展人类创造力的边界。
应用信息
分类
开发者
Stability AI
收录时间
2025-05-08
评论 (0)
暂无评论,快来发表第一条评论吧!