最新基准测试显示,英伟达 GB200 NVL72 系统在处理混合专家(MoE)模型时,性能高达 AMD MI355X 集群的28倍,且每 token 成本仅为后者的十五分之一。这一数据不仅确立了英伟达在超大规模推理领域的绝对统治力,也揭示了“极致协同设计”在解决通信瓶颈上的关键作用。
极致架构 破解 MoE 模型通信瓶颈
Signal65 发布的最新 SemiAnalysis InferenceMAX 报告,针对 Deepseek-R1 0528 混合专家(MoE)模型进行了深度评测。MoE 模型的优势在于能根据任务动态激活最匹配的“专家”模块,但在大规模扩展时,节点间的通信延迟往往成为致命瓶颈。
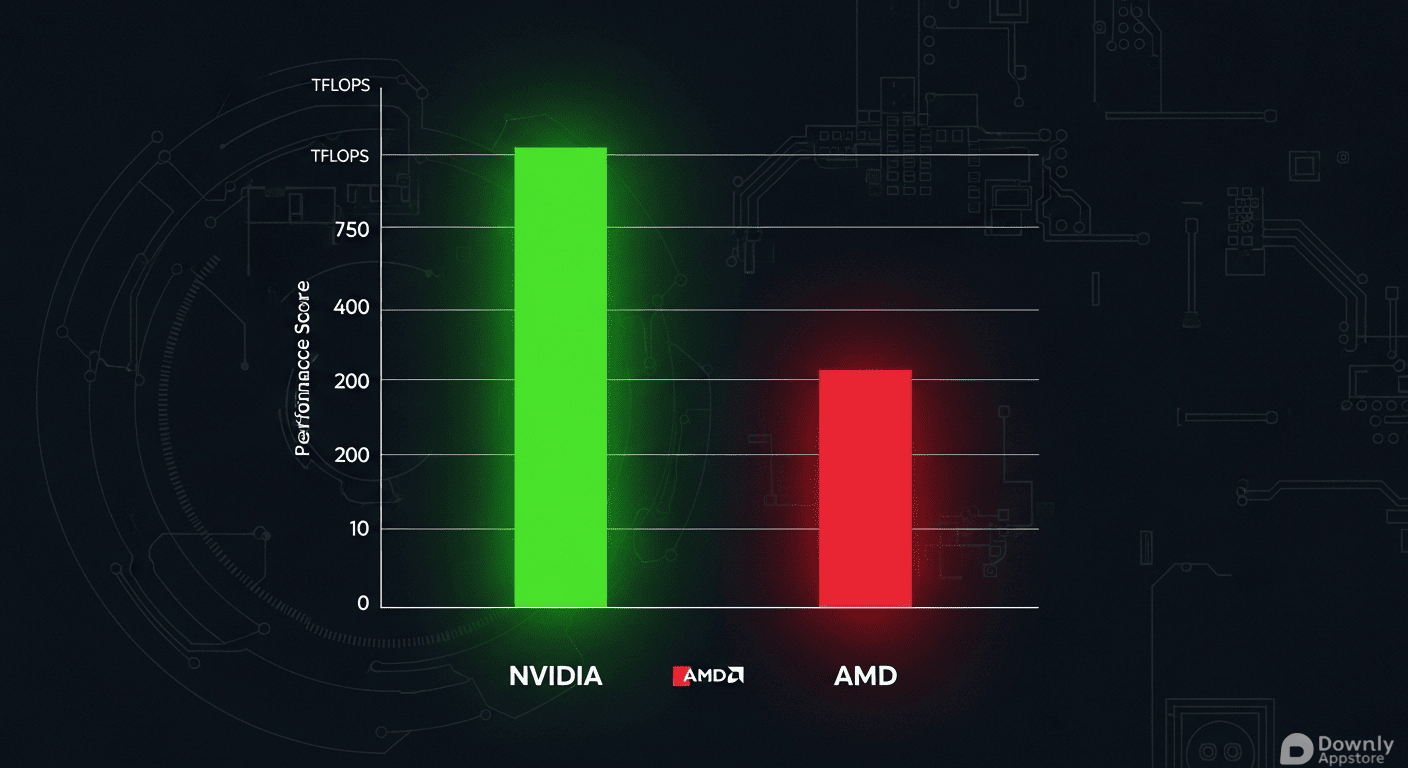
英伟达通过 GB200 NVL72 给出了教科书般的解决方案。该系统并未单纯堆砌算力,而是采用了“极致协同设计”策略,将72颗芯片紧密互联,并配备高达 30TB 的共享内存。这种设计彻底打通了数据传输的高速公路,显著降低了延迟。测试数据显示,在相似配置下,GB200 NVL72 的每个 GPU 吞吐量高达 75 tokens/秒,性能达到 AMD MI355X 的28倍。
成本效益 TCO 成为云厂商的核心考量
对于超大规模云计算厂商而言,单纯的性能指标不足以决定采购意向,整体拥有成本(TCO)才是关键。Signal65 结合 Oracle 云定价模型分析指出,GB200 NVL72 在提供极高交互速率的同时,展现了惊人的成本效益。
其每 token 的相对成本仅为 AMD 方案的十五分之一。这意味着在同等预算下,企业能够获得数十倍的算力产出,或者在满足同等业务需求时大幅削减硬件开支。这种“降本增效”的双重优势,使得 GB200 NVL72 在高端推理市场几乎没有对手。
错位竞争 AMD 坚守稠密模型阵地
尽管在 MoE 领域遭遇重挫,AMD 并非全无机会。报告强调,AMD 的 MI355X 凭借大容量 HBM3e 内存,在稠密模型(Dense Models)环境中依然具备极强的竞争力。
目前,AMD 尚未推出能与 GB200 NVL72 正面对抗的机架级解决方案。但随着 AMD Helios 平台与英伟达 Vera Rubin 平台的对决临近,双方在机架级扩展方案上的博弈将更加激烈。对于 AMD 而言,如何突破互联带宽限制,构建类似 NVL72 的高内聚系统,将是其能否在下一代计算竞赛中翻盘的关键。




2025 AI 技术峰会

AI 实战课程
热门工具
AI 助手
智能对话,提升效率
智能图像处理
一键美化,智能修图
AI 翻译
多语言实时翻译



评论 (0)
暂无评论,快来发表第一条评论吧!