在人工智能驱动的数字内容生成领域,如何让虚拟形象更加生动、自然地与用户互动,一直是技术探索的热点。近日,腾讯混元大模型团队推出了一个重磅开源项目——HunyuanVideo-Avatar。这项技术的核心在于能够仅凭一段语音,就驱动生成具有丰富表情和自然口型变化的数字人视频。这一创新不仅极大地降低了数字人视频制作的门槛,更为虚拟直播、教育、娱乐等多个领域带来了全新的可能性,标志着语音驱动数字人技术迈入了新的阶段。
腾讯混元大模型团队在人工智能领域持续发力,继文本生成图片、视频生成等技术之后,再次向开源社区贡献了重要的研究成果——HunyuanVideo-Avatar。这一项目的开源,旨在 democratize(民主化)数字人视频的生成过程,让更多开发者和使用者能够轻松地利用语音来驱动虚拟形象的生成。
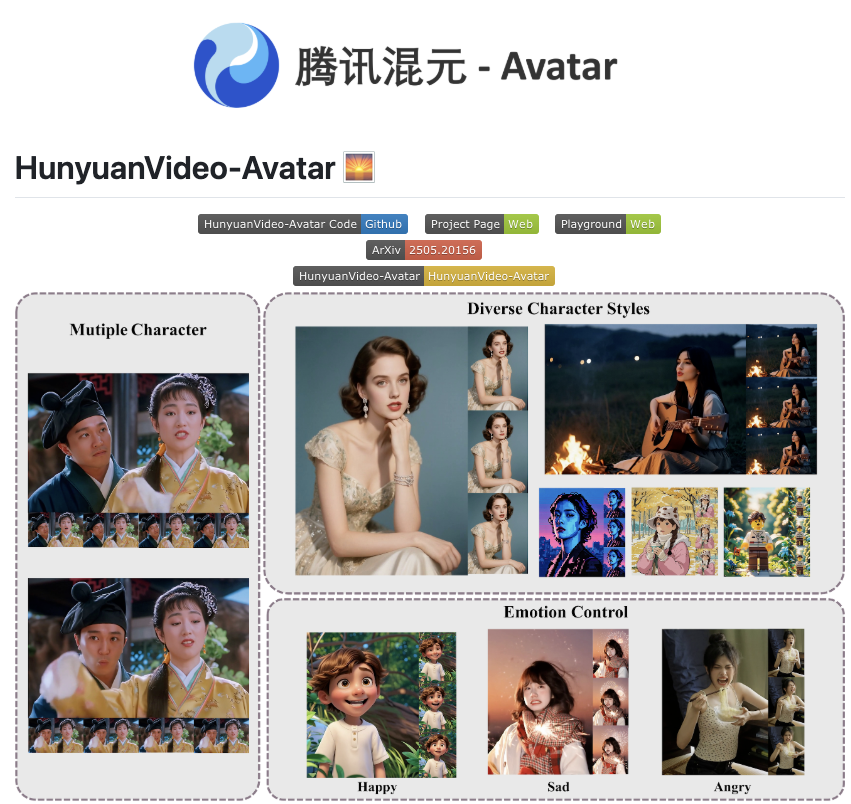
HunyuanVideo-Avatar 的核心功能正如其名 所言,能够实现“语音驱动生成数字人”。这意味着用户不再需要复杂的 3D 建模、动作捕捉或专业的视频编辑技能,只需要提供一段音频,系统就能够根据语音的内容、情感和语速,自动生成一个数字人说话的视频。这无疑是一项具有颠覆性的技术,将极大提升内容创作的效率和便捷性。
在线测试HunyuanVideo-Avatar:https://hunyuan.tencent.com/modelSquare/home/play?modelId=126
技术揭秘 语音如何“驱动”数字人
实现从音频到数字人视频的无缝转换,需要跨越多模态技术的壁垒。HunyuanVideo-Avatar 在技术上可能采用了以下几个关键组成部分
- 语音特征提取与分析 系统首先需要对输入的语音进行深入分析,提取出语音的语言内容、语调、情感以及与口型运动相关的声学特征。
- 面部动作与表情生成 基于语音特征,模型需要推断出数字人相应的面部动作、表情变化以及最关键的——口型变化。这需要对人脸的肌肉运动和语音发声机制有深刻的理解。
- 图像生成与渲染 最后,模型将生成或操纵数字人的图像,使其面部表情和口型与分析出的语音特征同步,最终输出一段连贯自然的数字人视频。
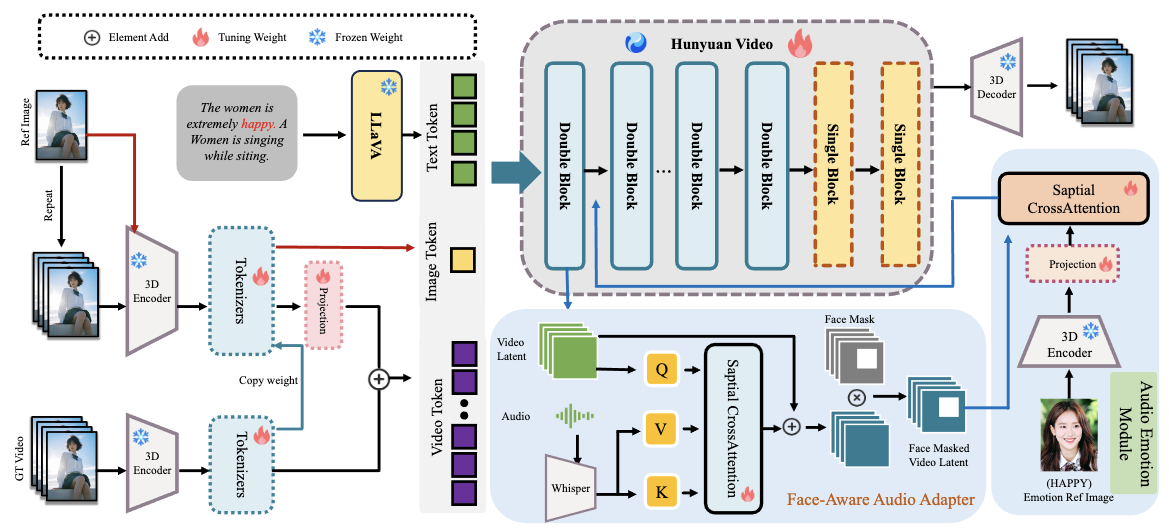
为了确保生成视频的自然度和逼真度,HunyuanVideo-Avatar 可能采用了先进的深度学习模型,如基于 Transformer 的架构、生成对抗网络(GAN)或扩散模型,并结合了大量的多模态数据集进行训练。论文中可能详细描述了其具体的模型结构和训练策略,例如可能采用了创新的注意力机制来对齐语音和视觉特征,或者使用了新的损失函数来优化生成视频的质量和一致性。
开源的价值 普惠 AI 的重要一步
腾讯选择将 HunyuanVideo-Avatar 开源,具有重要的战略意义和社区价值
- 加速技术普及与应用 开源使得更多的开发者和研究机构能够接触和使用这一先进技术,基于其进行二次开发和创新应用,从而加速语音驱动数字人技术的普及和落地。
- 激发社区创新活力 开源社区的力量是巨大的。 全球的开发者可以共同对 HunyuanVideo-Avatar 进行改进、优化和拓展功能,推动技术的快速迭代和演进。
- 构建开放生态 腾讯通过开源,有助于构建一个围绕混元大模型和数字人技术的开放生态系统,吸引更多合作伙伴共同参与,共同推动产业发展。
- 提升技术透明度 开源有助于提高技术的透明度,让使用者更加了解模型的原理和潜在限制,促进技术的健康发展。
HunyuanVideo-Avatar 的开源,是腾讯在践行“科技向善”理念、推动 AI 普惠化方面的重要一步,为降低数字内容创作门槛、赋能更多个体和企业提供了强大的工具。
广泛应用前景 数字人进入千家万户
HunyuanVideo-Avatar 的出现,将极大地拓展数字人的应用边界,为各行各业带来新的机遇
- 虚拟直播 个体创作者和品牌可以快速生成具有个性化形象的虚拟主播,降低直播成本,提升内容吸引力。
- 在线教育 创建生动有趣的数字老师,根据学生的语音输入进行互动式教学。
- 客服与导览 生成智能数字客服或虚拟导览员,提供更加人性化的服务体验。
- 娱乐与营销 制作创意短视频、广告或虚拟偶像,进行更具互动性和趣味性的内容传播。
- 个人表达与社交 未来用户甚至可以轻松创建自己的数字分身,用于社交互动和内容分享。

凭借语音驱动这一便捷高效的方式,HunyuanVideo-Avatar 有望让数字人不再是高门槛的技术,而是人人都可以轻松使用的工具,真正让数字人“走进千家万户”。
本地部署
需要支持CUDA的NVIDIA GPU
- 该模型在8GPU的机器上进行了测试。
- 最低配置:生成720px1280px129帧视频所需的最小GPU内存为24GB,但速度很慢。
- 推荐配置:我们建议使用80GB显存的GPU以获得更好的生成质量。
- 测试过的操作系统:Linux
🛠️ 依赖项和安装
首先克隆仓库:
git clone https://github.com/Tencent/HunyuanVideo-Avatar.git cd HunyuanVideo-Avatar
Linux安装指南
我们推荐使用CUDA 12.4或11.8版本进行手动安装。
Conda的安装说明可在这里找到。
# 1. 创建conda环境
conda create -n HunyuanVideo-Avatar python==3.10.9
# 2. 激活环境
conda activate HunyuanVideo-Avatar
# 3. 使用conda安装PyTorch和其他依赖
# 对于CUDA 11.8
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=11.8 -c pytorch -c nvidia
# 对于CUDA 12.4
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.4 -c pytorch -c nvidia
# 4. 安装pip依赖
python -m pip install -r requirements.txt
# 5. 安装flash attention v2以加速(需要CUDA 11.8或更高版本)
python -m pip install ninja
python -m pip install git+https://github.com/Dao-AILab/flash-attention.git@v2.6.3
如果在特定GPU类型上遇到浮点异常(核心转储),您可以尝试以下解决方案:
# 方案1:确保您已安装CUDA 12.4、CUBLAS>=12.4.5.8和CUDNN>=9.00(或直接使用我们的CUDA 12 docker镜像)
pip install nvidia-cublas-cu12==12.4.5.8
export LD_LIBRARY_PATH=/opt/conda/lib/python3.8/site-packages/nvidia/cublas/lib/
# 方案2:强制显式使用CUDA 11.8编译版本的PyTorch和所有其他包
pip uninstall -r requirements.txt # 卸载所有包
pip install torch==2.4.0 --index-url https://download.pytorch.org/whl/cu118
pip install -r requirements.txt
pip install ninja
pip install git+https://github.com/Dao-AILab/flash-attention.git@v2.6.3
此外,您也可以使用混元视频Docker镜像。使用以下命令拉取并运行docker镜像。
# 对于CUDA 12.4(更新以避免浮点异常)
docker pull hunyuanvideo/hunyuanvideo:cuda_12
docker run -itd --gpus all --init --net=host --uts=host --ipc=host --name hunyuanvideo --security-opt=seccomp=unconfined --ulimit=stack=67108864 --ulimit=memlock=-1 --privileged hunyuanvideo/hunyuanvideo:cuda_12
pip install gradio==3.39.0 diffusers==0.33.0 transformers==4.41.2
# 对于CUDA 11.8
docker pull hunyuanvideo/hunyuanvideo:cuda_11
docker run -itd --gpus all --init --net=host --uts=host --ipc=host --name hunyuanvideo --security-opt=seccomp=unconfined --ulimit=stack=67108864 --ulimit=memlock=-1 --privileged hunyuanvideo/hunyuanvideo:cuda_11
pip install gradio==3.39.0 diffusers==0.33.0 transformers==4.41.2
🧱 下载预训练模型
预训练模型的下载详情请参见这里。
🚀 多GPU并行推理
例如,要使用8个GPU生成视频,可以使用以下命令:
cd HunyuanVideo-Avatar
JOBS_DIR=$(dirname $(dirname "$0"))
export PYTHONPATH=./
export MODEL_BASE="./weights"
checkpoint_path=${MODEL_BASE}/ckpts/hunyuan-video-t2v-720p/transformers/mp_rank_00_model_states.pt
torchrun --nnodes=1 --nproc_per_node=8 --master_port 29605 hymm_sp/sample_batch.py \
--input 'assets/test.csv' \
--ckpt ${checkpoint_path} \
--sample-n-frames 129 \
--seed 128 \
--image-size 704 \
--cfg-scale 7.5 \
--infer-steps 50 \
--use-deepcache 1 \
--flow-shift-eval-video 5.0 \
--save-path ${OUTPUT_BASEPATH}
🔑 单GPU推理
例如,要使用1个GPU生成视频,可以使用以下命令:
cd HunyuanVideo-Avatar
JOBS_DIR=$(dirname $(dirname "$0"))
export PYTHONPATH=./
export MODEL_BASE=./weights
OUTPUT_BASEPATH=./results-single
checkpoint_path=${MODEL_BASE}/ckpts/hunyuan-video-t2v-720p/transformers/mp_rank_00_model_states_fp8.pt
export DISABLE_SP=1
CUDA_VISIBLE_DEVICES=0 python3 hymm_sp/sample_gpu_poor.py \
--input 'assets/test.csv' \
--ckpt ${checkpoint_path} \
--sample-n-frames 129 \
--seed 128 \
--image-size 704 \
--cfg-scale 7.5 \
--infer-steps 50 \
--use-deepcache 1 \
--flow-shift-eval-video 5.0 \
--save-path ${OUTPUT_BASEPATH} \
--use-fp8 \
--infer-min
低显存运行方案
cd HunyuanVideo-Avatar
JOBS_DIR=$(dirname $(dirname "$0"))
export PYTHONPATH=./
export MODEL_BASE=./weights
OUTPUT_BASEPATH=./results-poor
checkpoint_path=${MODEL_BASE}/ckpts/hunyuan-video-t2v-720p/transformers/mp_rank_00_model_states_fp8.pt
export CPU_OFFLOAD=1
CUDA_VISIBLE_DEVICES=0 python3 hymm_sp/sample_gpu_poor.py \
--input 'assets/test.csv' \
--ckpt ${checkpoint_path} \
--sample-n-frames 129 \
--seed 128 \
--image-size 704 \
--cfg-scale 7.5 \
--infer-steps 50 \
--use-deepcache 1 \
--flow-shift-eval-video 5.0 \
--save-path ${OUTPUT_BASEPATH} \
--use-fp8 \
--cpu-offload \
--infer-min
运行Gradio服务器
cd HunyuanVideo-Avatar
bash ./scripts/run_gradio.sh
未来展望 AI 驱动数字内容新浪潮
腾讯开源 HunyuanVideo-Avatar,是人工智能驱动数字内容生成浪潮中的一个重要里程碑。它不仅展示了腾讯在多模态 AI 领域的深厚技术积累,更通过开源的方式,将前沿技术分享给全球社区,共同推动数字人技术的创新和应用。
随着技术的不断发展和社区的共同努力,我们可以期待 HunyuanVideo-Avatar 在未来能够支持更多复杂的语音情绪、更细腻的面部表情以及更多样的数字人形象。这场由语音驱动的数字人新浪潮,才刚刚开始,它将深刻改变我们创作、消费和互动数字内容的方式。


2025 AI 技术峰会

AI 实战课程
热门工具
AI 助手
智能对话,提升效率
智能图像处理
一键美化,智能修图
AI 翻译
多语言实时翻译
评论 (0)
暂无评论,快来发表第一条评论吧!